


Identifying and Rectifying Human Error in Randomization Plan
Introduction
In clinical trials, accurate application of randomization is crucial for obtaining reliable results in the analysis of study data. However, human errors can significantly impact outcomes, leading to incorrect conclusions. This case study explores a scenario where human error in randomization led to discrepancies between the mean and standard deviation of glucose levels reported by KITE-Ai and Client analyses..
Background
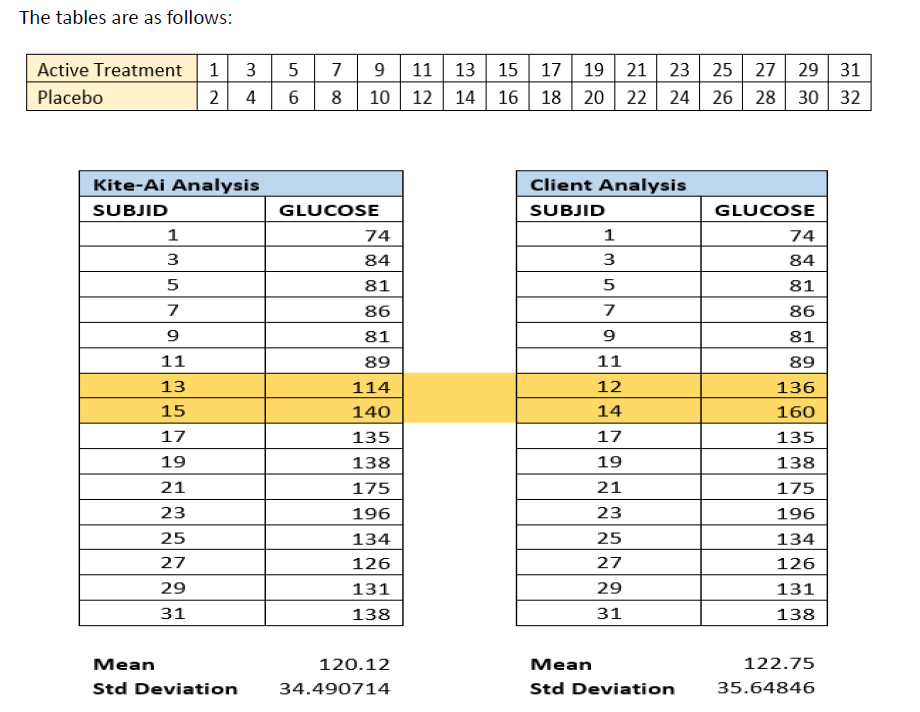
The data presented in this case study is from a diabetes study, where subjects were randomized to active treatment and placebo groups, focusing on glucose levels. Two tables were created, each containing two columns: SUBJID (subject ID) and Glucose Level. Analyses were conducted simultaneously by KITE-Ai and the Client. However, the mean and standard deviation of glucose levels reported by each team did not match, indicating a potential issue.
What we did?
The discrepancy was traced back to errors in randomization applied by the Client. Specifically:
- SUBJID 23 and SUBJID 27 were incorrectly included in Active Treatment arm.
- SUBJID 28 and SUBJID 31, who were supposed to be part of Active Treatment arm, were excluded.
This misallocation of subjects caused incorrect glucose level data to be used in the Client’s analysis, thereby affecting the final computed mean and standard deviation values.
*Dummy data used, and image is for representation purpose only. The actual data and visualization remain confidential as a part of the CDA and DECP.
Impact of Human Error
The incorrect randomization had significant consequences:
- The mean glucose level reported by KITE-AI-Ai was 120.12, whereas the Client reported 122.75.
- The standard deviation glucose level reported by KITE-Ai was 34.49071, while the Client reported 35.64846.
- The inclusion of incorrect subjects (SUBJID 23 and SUBJID 27) in the Client’s analysis introduced erroneous data, resulting in a higher mean value.
- These discrepancies could lead to incorrect conclusions about the efficacy or safety of the treatment under study.
Conclusion
This case study highlights the critical importance of accurate randomization in clinical trials. Human errors, such as incorrect subject inclusion, can result in significant discrepancies in data analysis, potentially jeopardizing the validity of the trial’s conclusions. It underscores the need for meticulous data management and rigorous verification processes to minimize the risk of such errors and ensure reliable results. Although the case study is from live studies, actual study data is not used here to protect data privacy and dummy is presented here for illustration.
Experience of delivering More than
200+ Studies
Under different therapeutic area
Team of experience Professionals
40+ programmers
With an average of 10+ years of experience
Building a joyful client relationship
10+ satisfied clients
Through a commitment to quality and trust.